Blakes 21 Days Chapter 19 Document
Day 19, Reading and Writing RSS Feeds
- Top
- 525 Today, you will work with Extensible Markup Language (XML), a popular and widely implemented formatting standard that enables data to be portable.
- 525 You explore XML in the following ways:
- Representing data as XML
- Discovering why XML is a useful way to store data
- Using XML to publish web content
- Reading and writing XML data
- 525 The XML format employed throughout the day is Really Simple Syndication (RSS),
- a popular way to publish web content and share information on site updates.
- RSS has been adopted by millions of sites.
Using XML
- Top
- 526 One of Java's main selling points is that the language produces programs that can run on different operating systems without modification.
- The portability of software is a big convenience in today's computing world, where Windows, Linux, Mac OS, iOS, Android, and other operating systems
- are in wide use and many people work with multiple systems.
- 526 XML is a format for storing and organizing data that is independent of any software program that works with data.
- 526 Data that is compliant with XML is easier to reuse for several reasons.
- 526 First, the data is structured in a standard way, making it possible for software to read and write the data as long as it supports XML.
- If you create an XML file that represents your company's employee database, several dozen XML parsers can read the file and make sense of its contents.
- 526 This is true no matter what kind of information you collect about each employee.
- If your database contains only the employee's name, ID number, and salary, XML parsers can read it.
- If it contained 25 items, including birthday, blood type, and hair color, parsers can read that too.
- 526 Second, the data is self-documenting, making it easier for people to understand a file's purpose by looking at it in a text editor.
- Anyone who opens your XML employee database should be able to figure out the structure and content of each employee record without any assistance from you.
First Listing - Listing 19.1
- 526 This is evident in Listing 19.1 which contains an RSS file.
- Because RSS is an XML dialect,it is structured under the rules of XML.
- Enter this code in NetBeans (category Other, type Empty File) and save it as workbench.rss.
- (You also can download a copy of it from the book's website at www.java21days.com on the Day 19 page.)
Listing 19.1 - The Full Text of workbench.rss
- Top
- page 526 - 527
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0">
<channel>
<title>Workbench</title>
<link>http://workbench.cadenhead.org/</link>
<description>Programming, publishing, and popes</description>
<docs>http://www.rssboard.org/rss-specification</docs>
<item>
<title>Programming Confidence Pool for the World Cup</title>
<link>http://workbench.cadenhead.org/news/739</link>
<pubDate>Wed, 11 Jun 2015 11:49:47 -0400</pubDate>
<guid isPermaLink="false">tag:cadenhead.org.2015:w.739</guid>
<enclosure length="2498623" type="audio/mpeg"
url="2498623">http://mp3.cadenhead.org/3679.mp3" />
</item>
<item>
<title>Ghost of Pool Computer Author Past</title>
<link>http://workbench.cadenhead.org/news/737</link>
<pubDate>Mon, 24 Mar 2014 17:00:13 -0400</pubDate>
<guid isPermaLink="false">tag:cadenhead.org.2015:w.737</guid>
</item>
<item>
<title>Interview with Zoe Zolbrod</title>
<link>http://workbench.cadenhead.org/news/736</link>
<pubDate>Fri, 21 Mar 2014 11:12:55 -0400</pubDate>
<guid isPermaLink="false">tag:cadenhead.org.2015:w.736</guid>
</item>
</channel>
</rss>
An Explanation
- Top
- 527 Can you tell what the data represents?
- Although the ?xml tag at the top might be indecipherable, the rest is clearly a website database of some kind.
- 527 The ?xml tag in the first line of the file has a version attribute with a value of "1.0" and an encoding attribute of "utf-8".
- This establishes that the file follows the rules of XML 1.0 and is encoded with the UTF-8 character set.
- 527 Data in XML is surrounded by tag elements that describe the data.
- Opening tags begin with a < character followed by the name of the tag and a > character.
- Closing tags begin with a </ characters followed by a name and a > character.
- In Listing 19.1, for example, <item> on line 8 is an opening tag, and </item> on line 15 is a closing tag.
- Everything within those tags is considered to be the values of that element.
- 527 Elements can be nested within other elements, creating a hierachy of XML data that establishes relationships within that data.
- In Listing 19.1, everything in lines 9-14 is related, each element defines something about the same website item.
- 527 Elements also can include attributes, which are made up of data that supplements the rest of the data associated with the element.
- Attributes are defined within an opening tag element.
- The name of an attribute is followed by an equal sign and text within quotation marks.
- 527 In line 12 of Listing 19.1, the guid element includes an isPermaLink attribute with a value of "false".
- This indicates that the element's value, tag:cadenhead.org.2015:w.739, is not a permalink, the URL at which the item can be loaded in a browser.
- Top
- 528 XML also supports elements defined by a single tag rather than a pair of tags.
- The tag begins with a < character followed by the name of the tag and ends with the /> characters.
- The RSS file includes an enclosure element in lines 13-14 that describes an MP3 audio file associated with the item.
- 528 XML encourages the creation of data that's understandable and usable
- even if the user doesn't have the program that created it and cannot find any documentation that describes it.
- 528 For the most part, you can understand the purpose of the RSS file shown in Listing 19.1 simply by looking at it.
- Each item represents a web page that has been updated recently.
- Top
- 528 TIP: Publishing new site content with RSS and a similar format, Atom, has become one of the best ways to build readership on the Web.
- Thousands of people subscribe to RSS files, which are called feeds, using reader software such as Feedly and My Yahoo!.
- Rogers Cadenhead, the author of this book, is the chairman of the RSS Advisory Board, the group that publishes the Rss 2.0 specification.
- For more information on the format, visit the board's website at www.rssboard.org or subscribe to its RSS feed at www.rssboard.org/rss-feed.
- Note: when browsing to www.rssboard/rss-feed the url in the browser changes to feeds.rssboard.org.
- There's also another version of RSS, RDF Site Summary, that's used on some sites for its feeds.
- 528 Data the follows XML's formatting rules is said to be well-formed.
- Any software that can work with XML reads and writes well-formed XML data.
- 528 By insisting on well-formed markup, XML simplifies the task of writing programs that work with the data.
- RSS makes website updates available in a form that software can easily process.
- The RSS feed for Workbench at http://feeds.cadenhead.org/workbench has two distinct audiences:
- humans reading the blog thru their preferred RSS reader,
- and computers that do something with this data.
- Twitter, Facebook, and many other sites can pull data from an RSS feed and present it to users.
Designing an XML Dialect
- Top
- 528 Although XML is described as a language and is compared to Hypertext Markup Language (HTML), it's actually much larger in scope.
- XML is a markup language that defines how to define a markup language.
- 529 That's an odd distinction to make, and probably sounds like something you'd encounter in a philosophy textbook.
- This concept is important to understand because it explains how XML can be used to define data
- as varied as health-care claims, genealogical records, newspaper articles, and molecules.
- 529 The X in XML stands for Extensible, and it refers to organizing data for your own purposes.
- Data that's organized using the rules of XML can represent anything you want:
- A programmer at a telemarketing company can use XML to store data on each outgoing call,
- saving the time of the call, the number, the operator who made the call, and the result.
- A hobbyist can use XML to keep track of the annoying telemarketing calls she receives,
- noting the time of call, the company, and the product being peddled.
- A programmer at a government agency can use XML to track complaints about telemarketers,
- saving the name of the marketing firm and the number of complaints.
- 529 Each of these examples uses XML to define a new language that suits a specific purpose.
- Although you could call them XML languages, they're more commonly described as XML dialects or XML document types.
- 529 An XML dialect can be designed using a document type definition (DTD) that indicates the potential elements and attributes it covers.
- 529 A special !DOCTYPE declaration can be placed in XML data, right after the initial ?xml tag, to identify its DTD.
- Here's an example:
<!DOCTYPE Library SYSTEM "librml.dtd">
- 529 The !DOCTYPE declaration is used to identify the DTD that applies to the data.
- When a DTD is present, many XML tools can read XML created for that DTD and determine whether the data follows all the rules.
- If it doesn't, it is rejected with a reference to the line that caused the error.
- This process is called validating the XML.
- 529 One thing you run into as you work with XML is data that has been structured as XML but wasn't defined using a DTD.
- Most versions of RSS files do not require a DTD.
- This data can be parsed (presuming it's well-formed), so you can read it into a program and do something with it, but you can't check its validity to make sure it's organized correctly according to the rules of its dialect.
Processing XML with Java
- Top
- 530 Java supports XML thru the Java API for XML Processing, a set of packages for reading, writing, and manipulating XML data.
- 530 The javax.xml.parsers package is the entry point to the other packages.
- These classes can be used to parse and validate XML data using two techniques: the Simple API for XML (SAX) and the Document Object Model (DOM).
- However, they can be difficult to implement, which has inspired other groups to offer their own class libraries to work with XML.
- 530 You spend the remainder of the day working with one of these alternatives:
- the XML Object Model (XOM) library, an open source Java class library that makes it extreamely easy to read, write, and transform XML data.
Processing XML with XOM
- Top
- 530 One of the most important skills you can develop as a Java programmer is the abilty to find suitable packages and classes that can be employed in your projects.
- For obvious reasons, using a well-designed class library is much easier than developing one on your own.
- 530 Although the Java Class Library contains thousands of well-designed classes that cover a comprehensive range of development needs,
- Oracle isn't the only supplier of classes that may prove useful to your efforts.
- 530 Other companies, groups, and individuals offer dozens of Java packages under a variety of commercial and open source licenses.
- Some of the most notable come from the Apache Software Foundation,
- whose Java projects include the web application framework Struts,
- the Java servlet container Tomcat, and the LogrJ logging class library.
- 531 Another terrific open source Java class libarary is the XOM library.
- This tree-based package for XML processing strives to be simple to learn, easy to use, and uncompromising in its adherence to well-formed XML.
- 531 The library was developed by the programmer and author Elliotte Rusty Harold based on his experience with XML processing in Java.
- 531 XOM originally was envisioned as a fork of JDOM, a popular tree-based model for representing an XML document.
- Harold contributed code to that open source project and participated in its development.
- But instead of forking the JDOM code, Harold decided to start from scratch and adopt some of its core design principles in XOM.
- Top
- 531 The library embodies the following principles:
- XML documents are modeled as a tree, with Java classes representing nodes on the tree such as
- elements, comments, processing instructions, and document type definitions.
- A programmer cann add and remove nodes to manipulate the document in memory, a simple approach that can be implemented gracefully in Java.
- All XML data produced by XOM is well-formed and has a well-formed namespace.
- Each element of an XML document is represented as a class with constructors.
- Object serialization is not supported.
- Instead, programmers are encouraged to use XML as the format for serialized data,
- enabling it to be readily exchanged with any software that reads XML,
- regardless of the programming language in which it was developed.
- The library relies on another XML parser to read XML documents and fill trees.
- XOM uses a SAX parser that must be downloaded and installed separately.
- Apache Xerces 2.6.1 and later versions should work.
- Top
- 531 XOM is available for download from www.xom.nu.
- The current version is 1.2.10, which includes Xerces 2.8 in its distribution.
- 531 CAUTION: XOM is released under the open source GNU Lesser General Public License (LGPL),
- which grants permission to distribute the library without modification with Java programs that use it.
- You also can make changes to the XOM class library as long as you offer them under the LGPL.
- 532 XOM can be downloaded as a ZIP or TAR.GZ archive.
- Download the library and extract the files on a folder on your computer, then follow these steps to add it to NetBeans:
- Choose Tools, Libraries. The Ant Library Manager opens.
- Click New Library. The New Library dialog appears.
- Enter XOM 1.2.10 as the Library Name, and click OK.
- Back in Ant Library Manager, click Add JAR/Folder.
- Browse to the folder where you extracted the XOM archive, and open it.
- In that folder, choose the file xom-1.2.10.jar.
- Click Add JAR/Folder.
- In the Ant Library Manager, click OK.
- 532 After you have added the libaray to NetBeans, you need to add it to the current project so that you can use XOM classes in your programs:
- In the Projects pane, scroll down past the .java files until you see a folder named Libraries.
- Right-click this folder and choose Add Library. The Add Library dialog appears.
- Choose XOM 1.2.10, and click OK.
- 532 An item for XOM appears under Libraries in the Projects pane.
Creating an XML Document
- Top
- 532 The first application you develop today, RssWriter, creates an XML document that contains the start of an RSS feed.
- The document is shown in Listing 19.2. (You don't have to type in this listing.)
Listing 19.2 - The Full Text of feed.rss
- Top
- page 532
<?xml version="1.0"?>
<rss version="2.0">
<channel>
<title>Workbench</title>
<link>http://workbench.cadenhead.org/</link>
</channel>
</rss>
- Top
- 533 The base nu.xom package contains classes for a complete XML document (Document)
- and the nodes of a document can contain (Attribute, Comment, DocType, Element, ProcessingInstruction, and Text).
- 533 The RssStarter application uses several of these classes.
- First, an Element object is created by specifying the element's name as an argument:
Element rss = new Element("rss");
- 533 This statement creates an object for the root element of the document, rss.Element's one-argument constructor
- can be used because the document does not employ a feature of XML called namespaces,
- if it did, a second argument would be necessary: the element's namespace uniform resource identifier (URL).
- The other classes in the XOM library supports namespaces in a similar manner.
- 533 In the XML document in Listing 19.2, the rss element includes an attribute named version with the value "2.0".
- An attribute can be created by specifying its name and value in consecutive arguments:
Attribute version = new Attribute("version", "2.0");
- 533 Attributes are added to an element by calling its addAttribute() method with the attribute as the only argument:
rss.addAttribute(version);
- 533 The text contained within an element is represented by the Text class, which is constructed by specifying the text as a String argument:
Text totleText = new Text("Workbench");
- 533 When an XML document is composed, all its elements end up inside a root element that is used to create a Document object -
- a Document constructor is called with the root element as an argument.
- In the RssStarter application, this element is called rss.
- Any Element object can be the root of a document:
Document doc = new Document(rss);
- Top
- 533 In XOM's tree structure, the classes representing an XML document and its constituent parts
- are organized into a hierarchy below the generic superclass nu.xom.Node.
- This class has three subclasses in the same package: Attributes, LeafNode, and ParentNode.
- 533 To add a child to a parent node, call the parent's appendChild() method with the node to add as the only argument.
- The following code creates two elements - a parent called channel and one child element, link:
Element channel = new Element("channel");
Element link = new Element("link");
Text linkText = new Text("http://workbench.cadenhead.org/");
link.appendChild(linkText);
channel.appendChild(link);
- Top
- 534 The appendChild() method appends a new child below all other children of that parent.
- The preceding statements produce this XML fragment:
<channel>
<link>http://workbench.cadenhead.org/</link>
</channel>
- 534 The appendChild() method also can be called with a String argument instead of a node.
- A Text object representing the string is created and added to the element:
link.appendChild("http://workbench.cadenhead.org/");
- 534 After a tree has been created and filled with nodes, it can be displayed by calling the Document method toXML(),
- which returns the complete and well-formed XML document as a String.
- 534 Listing 19.3 shows the complete application.
- Create the RssStarter class in the com.java21days package in NetBeans with this listing as the source.
Listing 19.3 - The Full Text of RssStarter.java
package com.java21days;
import java.io.*;
import nu.xom.*;
public class RssStarter {
public static void main(String[] arguments) {
// create an element to serve as the document's root
Element rss = new Element("rss");
// add a version attribute to the element
Attribute version = new Attribute("version", "2.0");
rss.addAttribute(version);
// create a element and make it a child of
Element channel = new Element("channel");
rss.appendChild(channel);
// create the channel's title tag with brackets
Element title = new Element("title");
Text titleText = new Text("Workbench");
title.appendChild(titleText);
channel.appendChild(title);
// create the channel's link tag with brackets
Element link = new Element("link");
Text 1Text = new Text("http://workbench.cadenhead.org/");
link.appendChild(1Text);
channel.appendChild(link);
// create a new document with as the root element
Document doc = new Document(rss);
// Save the XML document
try (
FileWriter fw = new FileWriter("feed.rss");
BufferedWriter out = new BufferedWriter(fw);
) {
out.write(doc.toXML());
} catch (IOException ioe) {
System.out.println(ioe.getMessage());
}
System.out.println(doc.toXML());
}
}
- I had to replace the angle brackets around title with title tag because the other way will not display the source code
- the word title (with the < > brackets), is not allowing the rest of the code to be displayed.
- So the listing displayed below, is an image from the link for the listing from the Chapter 19 Page.

- Top
- 535 The RssStarter application displays the XML document it creates on standard output and saves it to a file called feed.rss.
- The output is shown in Figure 19.1
Figure 19.1 - Creating an XML document with XOM. - goes here
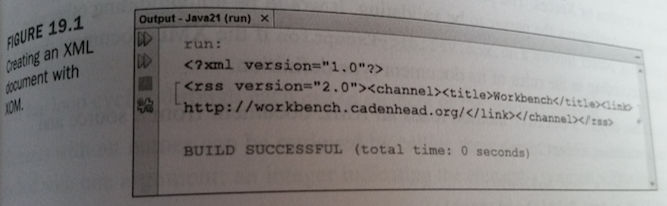
- Top
- 535 XOM automatically precedes a document with an XML declaration.
- 535 As you can see in Figure 19.1 the XML produced by this application contains no indentation, elements are stacked on the same line.
- 535 CAUTION: XOM preserves significant white space only when representing XML data.
- The spaces between elements in the RSS feed contained in Listing 19.2
- are strictly for presentation purposes and are not produced automatically when XOM creates an XML document.
- A subsequent example demonstrates how to control indentation.
Modifying an XML Document
- Top
- 536 The next project, the DomainEditor application, makes several changes to the XML document that was just produced bt the RssStarter application, feed.rss.
- The text enclosed by the link element is changed, and a new item element is added:
<item>
<title>Free the Bound Periodicals</title>
</item>
- 536 Using the nu.xom package, XML documents can be loaded into a tree from several sources:
- a File, InputStream, Reader, or URL (which is specified as a String instead of a java.net.URL object).
- 536 The Builder class represents a SAX parser that can load an XML document into a Document object.
- Constructors can be used to specify a particular parser or to let XOM use the first avialable parser from this list:
- Xerces2, Crimson, Piccolo, GNU Aelfred, Oracle, XP, Saxon Aelfred, or Dom4J Aclfred.
- If none of these is found, the parser specified by the system property org.xml.sax.driver is used.
- Constructors also determine whether the parser is validating or nonvalidating.
- 536 The Builder() and Builder(true) constructors both use the default parser -
- most likely a version of Xerces.
- The presence of the Boolean argument true in the second constructor configures the parser to be validating.
- It would ne nonvalidating otherwise.
- A validating parser throws a nu.xom.ValidityException if the XML document doesn't validate according to the rules of its document type definition.
- 536 The Builder object's build() method loads an XML document from a source and returns a Document object:
Builder builder = new Builder();
File xmlFile = new File("feed.rss");
Document doc = builder.build(xmlFile);
- 536 These statements load an XML document from the file feed.rss barring one of two problems:
- A mu.xom.ParseException is thrown if the file does not contain well-formed XML,
- and a java.io.IOException is thrown if the input operation fails.
- Top
- 536 Elements are retrieved from the tree by calling a method of their parent node.
- 536 A Document object's getRootElement() method returns the document's root element:
Element root = doc.getRootElement();
- 536 In the XML document feed.rss, the root element is domains.
- 537 Elements with names can be retrieved by calling their parent's node's getFirstChildElement() method
- with the nameas a String argument:
Element channel = root.getFirstChildElement("channel");
- 537 This statement retrieves the channel element contained in the rss element (or null if that element could not be found).
- Like other examples, this is simplified by the lack of a namespace in the document;
- there also are methods where a name and namespace are arguments.
- 537 When several elements within a parent have the same name, the parent node's getChildElements() method can be used instead:
Element children = channel.getChildElements();
- 537 The getChildElements() method returns an Elements object containing each of the elements
- This object is a read-only list and does not change automatically if the parent node's contents change after getChildElements() is called.
- 537 Elements has a size() method containing an integer count of the elements it holds.
- This can be used to loop to cycle thru each element in turn,
- beginning with the one at position 0.
- There's a get() method to retrieve each element;
- call it with the integer position of the element to be retrieved:
for (int i = 0; i < children.size(); i++) {
Element link = children.get(i);
}
- 537 This for loop cycles thru each child element of the channel element.
- 537 Elements without names can be retrieved by calling their parent node's getChild() method with one argument:
- an integer indicating the element's position within the parent node:
Text linkText = (Text) link.getChild(0);
- 537 This statement creates the Text object for the text "http://workbench.cadenhead.org/" found within the link element.
- Text elements always are at position 0 within their enclosing parent.
- 537 To work with this text as a string, call the Text object's getValue() method, as in this statement:
if (linkText.getValue().equals("http://workbench.cadenhead.org/"))
// ...
}
- Top
- 538 The DomainEditor application only modifies a link element enclosing the text "http://workbench.cadenhead.org/".
- The application makes the following changes:
- The text of the link element is deleted, the new text "http://www.cadenhead.org/" is added in its place,
- and then a new item element is added.
- reserve
- 538 A parent node has two removeChild() methods to delete a child node from the document.
- Calling the method with an integer deletes the child at that position:
Element channel = domain.getFirstChildElement("channel");
Element link = dna.getFirstChildElement("link");
link.removeChild(0);
- 538 These statements would delete the Text object contain within the channel's first link element.
- 538 Calling the removeChild() method with a node as an argument deletes that particular node.
- Extending the previous example, the link element could be deleted with this statement:
channel.removeChild(link);
- 538 Listing 19.4 shows the souce code of the DomainEditor application.
- Create this class in NetBeans in the com.java21days package.
Listing 19.4 - The Full Text of DomainEditor.java
package com.java21days;
import java.io.*;
import nu.xom.*;
public class DomainEditor {
public static void main(String[] args) throws IOException {
try (
// create a tree from the XML document feed.rss
Builder builder = new Builder();
File xmlFile = new File("feed.rss");
Document doc = builder.build(xmlFile);
// get the root element rss
Element root = doc.getRootElement();
// get its channel element
Element channel = root.getFirstChildElement("channel");
// get its link element
Element children = channel.getChildElements();
for (int i = 0; i < children.size(); i++) {
// get a link element
Element link = children.get(i);
// get its text
Text linkText = (Text) link.getChild(0);
// update any link matching a URL
if (linkText.getValue().equals(
"http://workbench.cadenhead.org/")) {
// update the link's text
link.removeChild(0);
link.appendChild("http://www.cadenhead.org/");
}
}
//create new elements and attributes to add
Element item = new Element("item");
Element itemTitle = new Element("title");
//add them to the channel element
itemTitle.appendChild(
"Free the Bound Periodicals"
item.appendChild(itemTitle);
channel.appendChild(item);
//Save the XML document
try (
FileWriter fw = new FileWriter("feed2.rss");
BufferedWriter out = new BufferedWriter(fw);
) {
out.write(doc.toXML());
} catch (IOException ioe) {
System.out.println(ioe.getMessage());
}
System.out.println(doc.toXML());
} catch (ParsingException pe) {
System.out.println("Parse error: " + pe.getMessage());
pe.printStackTree());
System.exit(-1);
}
}
}
- Top
- 539 The DomainEditor application displays the modified XML document to standard output and saves it to a file named feed2.rss.
- You can see the program's output in Figure 19.2
Figure 19.2 - Loading and modifying an XML document. - goes here
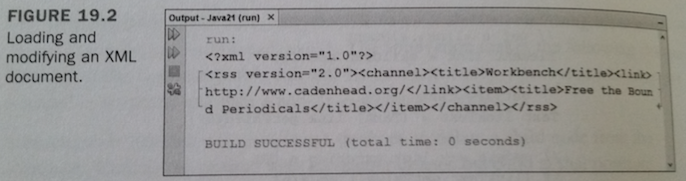
Formatting an XML Document
- Top
- 540 As described earlier, XOM does not retain insignificant white space when representing XML documents.
- This is in keeping with one of XOM's design goals -
- to disregard anything that has no syntactic significance in XML.
- (Another example of this is how text is treated identically whether it is created using character entities
- CDATA sections, or regular characters.)
- 540 Today's next project is the DomainWriter application.
- This program adds a comment to the beginning of the XML document feed2.rss and serializes it with indented lines,
- producing the version shown in Listing 19.5
Fifth Program - Listing 19.5 The Full Text of feed2.rss
- Top
- page 540
<?xml version="1.0" encoding="ISO-8659-1"?>
<!-- File created Sat Sep 26 21:17:49 EDT 2015-->
<rss version="2.0">
<channel>
<title>Workbench</title>
<link>http://workbench.cadenhead.org/</link>
<item>
<title>Free the Bound Periodicals</title>
</item>
</channel>
</rss>
- Top
- 540 The Serializer class in nu.xom offers control over how an XML document is formatted when it is displayed or stored serially.
- Indentation, character encoding, line breaks, and other formatting are established by objects of this class.
- 540 You can create a Serializer object by specifying an output stream and character encoding as arguments to the constructor:
FileOutputStream fos = new FileOutputStream("feed3.rss");
Serializer output = new Serializer(fos, "ISO-8859-1");
- 541 These statements serialize a file using the ISO-8859-1 character encoding.
- 541 Serializer supports 22 encodings, including ISO-10646-UCS-2, ISO-8859-1 through ISO-8859-10, ISO-8859-16, UTF-8, and UTF-16.
- There's also a Serializer() constructor that takes only an output stream as an argument, this uses the UTF-8 encoding by default.
- 541 You set indentation by calling the serializer's setIndentation() method with an integer argument specifying the number of spaces.
output.set.Indentation(2);
- 541 You can write an entire XML document to the serializer destination by calling the serializer's write() method with the document as an argument:
- 541 The DomainWriter application inserts a comment atop the XML document instead of appending it at the end of a parent node's children.
- This requires another method of the parent node, insertChild(), which is called with two arguments -
- the element to add and the integer position of the insertion:
Builder builder = new Builder();
Document doc = builder.build(arguments(0));
Comment timestamp = new Comment("File created " +
new java.util.Date());
doc.insertChild(timestamp, 0);
- 541 The comment is placed at postion 0 atop the document, moving the domains tag down one line but remaining below the XML declaration.
- 541 Listing 19.6 is the application's source code.
Listing 19.6 The Full Text of DomainWriter.java
package com.java21days;
import java.io.*;
import nu.xom.*;
public class DomainWriter {
public static void main(String[] args) throws IOException {
try (
// create a tree from an XML document
// specified as a command-line argument
Builder builder = new Builder();
File xmlFile = new File("feed2.rss");
Document doc = builder.build(xmlFile);
// Create a comment with the current time and date
Comment timestamp = new Comment("File created "
+ new java.util.Date());
// Add the comment above everything else in the
// document
doc.insertChild(timestamp, 0);
// Create a file output stream to a new file
FileOutputStream f = new FileOutputStream("feed3.rss");
// Using a serializer with indentation set as 2 spaces
// write the XML document to the file
Serializer output = new Serializer(f, "ISO-8859-1");
output.setIndent(2);
output.write(doc);
} catch (ParsingException pe) {
System.out.println("Parse error: " + pe.getMessage());
pe.printStackTree());
System.exit(-1);
}
}
}
- Top
- 542 The DomainWriter applications reads the file feed2.rss as input and creates a new modified version called feed3.rss.
Evaluating XOM
- Top
- 542 The applications you've created cover the core features of the main XOM package and are representative of its straightforward approach to XML processing.
- 542 There are also smaller nu.xom.canonical, nu.xom.converters, nu.xom.xinclude, and nu.xom.xslt packages
- to support XInclude, Extensible Stylesheet Language Transformations (XSLT), canonical XML serialization,
- and conversions between the XOM model for XML and the one used by DOM and SAX.
- 542 Listing 19.7 is an application that works with XML from a dynamic source:
- RSS feeds of recently updated web content from the feed's producer.
- The RssFilter application searches the feed for specific text in headlines, producing a new XML document that contains only the matching items and shorter indentation.
- It also modifies the feed's title and adds an RSS 0.91 document type declaration if one is needed in an RSS 0.91 format feed.
- 542 Create the RssFilter application in the com.java21days package in NetBeans.
Listing 19.7 The Full Text of RssFilter.java
package com.java21days;
import nu.xom.*;
public class RssFilter {
public static void main(String[] arguments) {
if (arguments.length < 2) {
System.out.println("Usage: java RssFilter file term");
System.exit(-1);
}
// Save the RSS location and search term
String rssFile = arguments[0];
String term = arguments[1];
try {
// Fill a tree with an RSS file's XML data
// The file can be local or something on the
// Web accessible via a URL.
Builder bob = new Builder();
Document doc = bob.build(rssFile);
// Get the file's root element ()
Element rss = doc.getRootElement();
// Get the element's version attribute
Attribute rssVersion = rss.getAttribute("version");
String version = rssVersion.getValue();
// Add the DTD for RSS 0.91 feeds, if needed
if ( (version.equals("0.91")) &
(doc.getDocType() == null) ) {
DocType rssDtd = new DocType("rss",
"http://my.netscape.com/publish/formats/rss-0.91.dtd");
doc.insertChild(rssDtd, 0);
}
// Get the first (and only) element
Element channel = rss.getFirstChildElement("channel");
// Get its element
Element title = channel.getFirstChildElement("title");
Text titleText = (Text) title.getChild(0);
// Change the title to reflect the search term
titleText.setValue(titleText.getValue() +
": Search for " + term + " articles");
// Get all of the - elements and loop through them
Elements items = channel.getChildElements("item");
for (int i = 0; i < items.size(); i++) {
// Get an
- item element
Element item = items.get(i);
// Look for a title element inside it
Element iTitle = item.getFirstChildElement("title");
// If found, look for its contents
if (iTitle != null) {
Text iTitleText = (Text) iTitle.getChild(0);
// If the search text is not found in the item,
// delete it from the tree
if (iTitleText.toString().indexOf(term) == -1) {
channel.removeChild(item);
}
}
}
// Display the results with a serializer
Serializer output = new Serializer(System.out);
output.setIndent(2);
output.write(doc);
} catch (Exception exc) {
System.out.println("Error: " + exc.getMessage());
exc.printStackTrace();
}
}
}
- Top
- 544 Run the application after setting the command-line arguments by selecting Run, Set Project Configuration, Customize.
- The first argument is the feed to check, and the second is the word to serach for in its titles.
- One feed that can be used to test the application is http://feeds.sportsfilter.com/sportsfilter from the SportsFilter weblog.
- Check it for a word such as soccer, NFL, Yankees, or Cowboys.
- 544 Partial output of using RssFilter to look for "NFL" in SportsFilter's RSS feed is displayed in Figure 19.3
- 544 Comments in the application's source code describe its functionality.
- 544 XOM's design is strongly informed by one overriding principle: enforced simplicity.
Figure 19.3 - Reading XML data from a website's RSS feed. - goes here

- Top
- 545 On the website for the class library, Elliotte Rusty Harold states that
- XOM "should help inexperienced developers do the right thing and keep them from doing the wrong thing.
- The learning curve needs to be really shallow, and that includes not relying on the best practices that are known in the community but are not obvious at first glance."
- 545 The new class library is useful for Java programmers whose programs require a steady diet of XML.
Summary
- Top
- 545 Today you learned the basics of another popular format for data representation,
- Extensible Markup Language (XML), by exploring one of the most popular uses of XML - RSS feeds.
- 545 In some ways, XML is the data equivalent of the Java language.
- It liberates data from the software used to create it and the operating system the software runs on,
- just as Java can liberate software from a particular operating system.
- 545 By using a class library such as the open source XML Object Model (XOM) library,
- you can easily create and retrieve data from an XML file.
- 545 A big advantage of representing data using XML is that you can always get that data back.
- If you decide to move the data into a relational database or some other form,
- you can easily retrieve the information
- The data being produced as RSS feeds can be mined bu software in countless ways, today and in the future.
- 545 You also can transform XML into other forms such as HTML thru a variety of texhnology,
- both in Java and thru tools developed in other languages.
Q & A
- Top | page 546
- Q What's the difference between RSS 1.0, RSS 2,0 and Atom ?
- A RSS 1.0 is a syndication format that employs the Resource Description Framework (RDF) to describe items in the feed.
- RSS 2.0 shares a common origin with RSS 1.0 but does not make use of RDF.
- Atom is another syndication format that was created after RSS 1.0 and RSS 2.0
- The Internet Engineering Task Force (IETF) has adopted Atom as an Internet standard.
- All three formats are suitable for offering web content in XML
- that can be read with a reader such as Feedly or My Yahoo! or that can be read by software
- and stored, manipulated, or transformed.
- Q Why is Extensible Markup Language called XML instead of EML ?
- A None of the founders of the language appears to have documented the reason for choosing XML as the acronym.
- The general consensus in the XML community is that it was choosen because it "sounds cooler" than EML.
- Before you snicker at that explanation, the creator of the language you are learning
- chose the name Java for its programming language using the same criteria,
- turning down more technical-sounding alternatives such as DNA and WRL.
- (The name Ruby was also considered and rejected, but later was chosen for another language.)
- Is's possible that the founders of XML
- were trying to avoid confusion with a programming language called EML (Extended Machine Language), which predates XML.
Quiz - Questions
- Top | page 546 | Review today's material by taking this three-question quiz.
- What does RSS stand for ?
- Really Simple Syndication
- RDF Site Summary
- Both
- What method cannot be used to add text to an XML element using XOM ?
- addAttribute(String, String)
- appendChild(Text)
- appendChild(String)
- When all the opening element tags, closing element tags, and other markup are applied consistently in a document, what adjective describes the document ?
- Validating
- Parsable
- Well-formed
Answers
- Top | Note A is 1, B is 2, and C is 3
- C. One version, RSS 2.0 claims Really Simple Syndication as its name. The other, RSS 1.0 claims RDF Site Summary.
- A. Answers B and C both work. One adds the contents of a Text element as the element's character data, and the other adds the string.
- C. The data to be considered XML, it must be well-formed.
Certification Practice
- Top
- 092 The following question is the kind of thing you could expect to be asked on a Java programming certification test. Answer it without looking at today's material or using the Java compiler to test the code.
- The answer is available on the book's website at www.java21days.com
- Given:
public class NameDirectory {
String[] names;
int nameCount;
public NameDirectory() {
names = new String[20];
nameCount = 0;
}
public void addName(String newName) {
if (nameCount < 20) {
// answer goes here
}
}
}
- The NameDirectory class must be able to hold 20 different names. What statement should replace // answer goes here for the class to function correctly ?
- names[nameCount] = newName;
- names[nameCount] =+ newName;
- names[nameCount++] = newName;
- names[++nameCount] = newName;
Exercise
- Top
- To extend your knowledge of the subjects covered today, try the following exercises:
- Create a simple XML format to represent a book collection with three books and a Java application that searches fro books with George R. R. Martin as the author, displaying any that it finds.
- Create two applications:
- one that retrieves records from a database and produces an XML file that contains the same information,
- and a second application that reads data from that XML file and displays it.